|
I am a Research Scientist at Meta Superintelligence Lab (FAIR, dotted line to TBD Lab), focusing on pretraining data. I am a core contributor to the Llama and Avocado models and the main POC for STEM multimodal pretraining. Meanwhile, I work closely with Shuchao Bi on advanced reasoning for post-training and Jason Wei on health pretraining. My work centers on STEM knowledge data at pre-training and mid-training scale, and on advanced reasoning for mid-training and RL. My research interests are large-scale pretraining data sourcing and curation pipelines, and using AI for AI — self-improvement algorithms, synthetic data, data feedback loops, and data-centric AI. I earned my Ph.D. under the guidance of Prof. Chenliang Xu at the University of Rochester.
Email / CV / Biography / Google Scholar / LinkedIn |

|

|
|
|
10M+ lifetime GPU-hours model training. Let the GPUs burn. 🔥 One paper about generative agent to augment target training datasets for model fine-tuning has been accepted for ICLR 2025. A series of Avatar animation works have been accepted for presentation at ECCV 2024 and Siggraph Asia 2024. I am serving as Area Chair in AI for the Content Creation Workshop in CVPR 2024.
One paper about conditional image generation is conditionally accepted to Siggraph Asia 2023. |

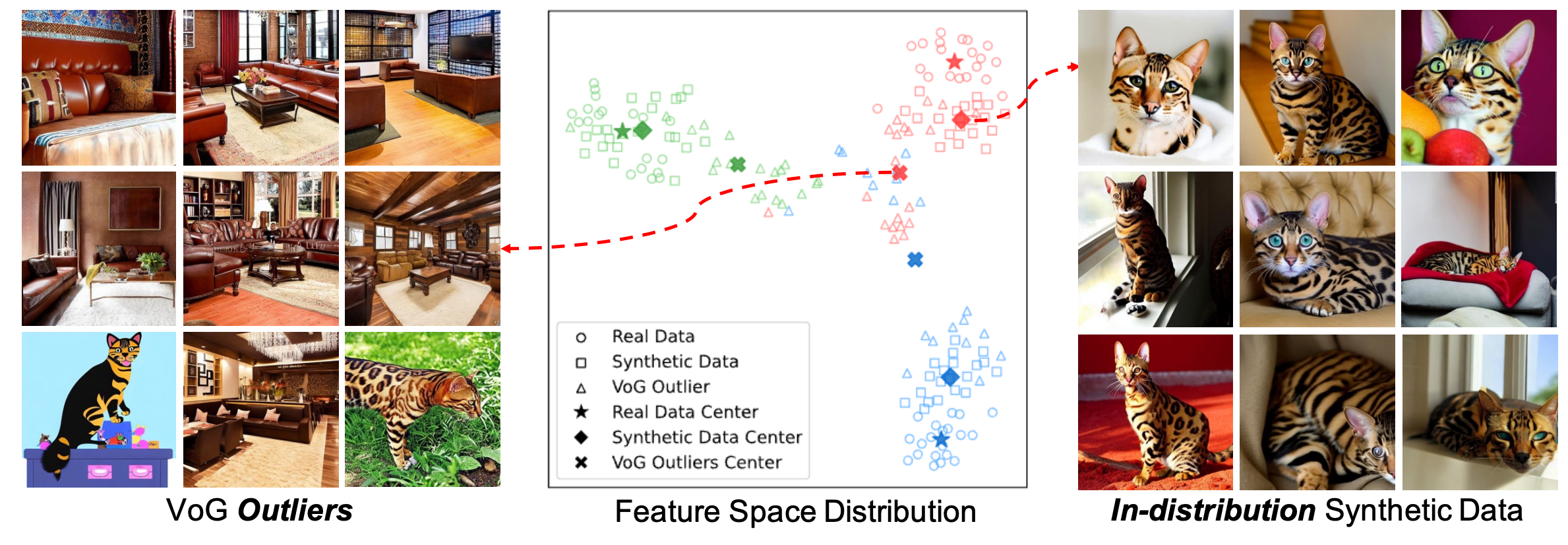 |
Zhiteng Li, Lele Chen ,Jerone T. A. Andrews, Yunhao Ba, Yulun Zhang, Alice Xiang ICLR 2025 paperWe propose a generative agent that augments training datasets with synthetic data for model fine-tuning. Unlike prior work, which uniformly samples synthetic data, our agent iteratively generates relevant samples on-the-fly, aligning with the target distribution. It prioritizes synthetic data that complements difficult training samples, focusing on those with high variance in gradient updates. Experiments across several image classification tasks demonstrate the effectiveness of our approach. |
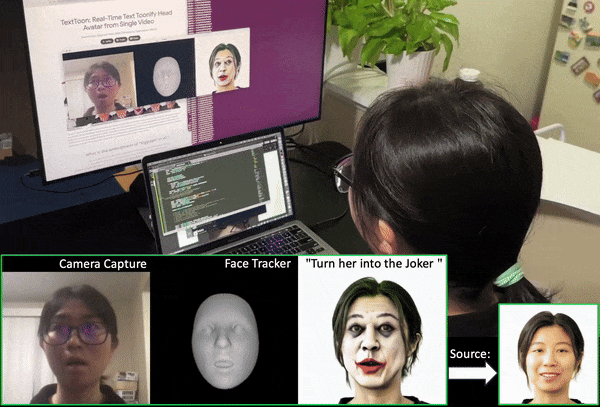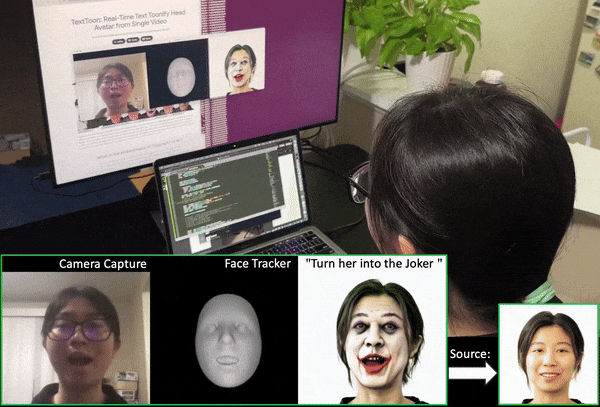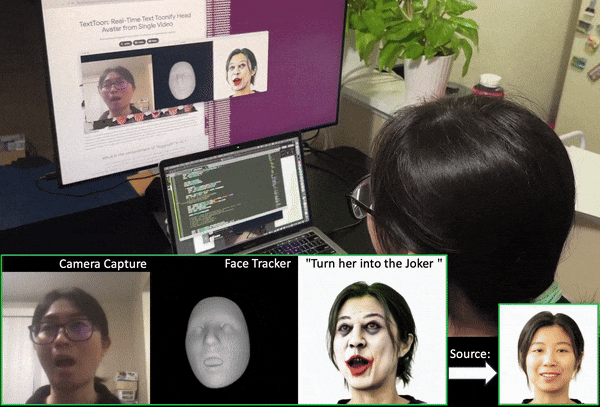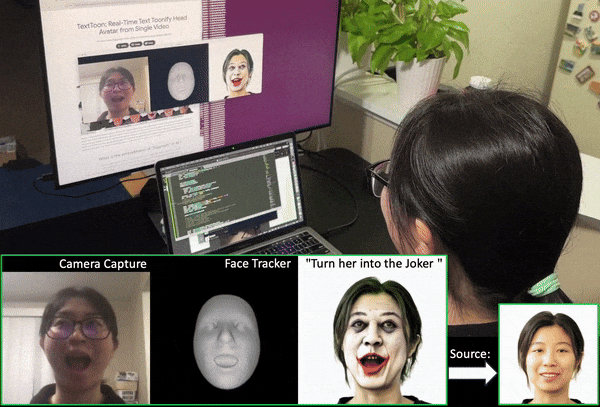 |
We propose a method to generate a drivable toonified avatar. Given a short monocular video sequence and a written instruction about the avatar style, our model can generate a high-fidelity toonified avatar that can be driven in real time by another video with arbitrary identities. Here, we present a real-time demo using an Apple Macbook Pro (M1 Chip). |
 |
In this manuscript, we introduce a method for modifying elements within a 3D scene based on guidance from language, masks, or bounding boxes. This innovative approach paves the way for compelling opportunities to enhance and tailor 3D objects. |
 |
Recent years have witnessed considerable achievements in facial avatar reconstruction with neural volume rendering. Despite notable advancements, the reconstruction of complex and dynamic head movements from monocular videos still suffers from capturing and restoring fine-grained details. In this work, we propose a novel approach, named Tri2-plane, for monocular photo-realistic volumetric head avatar reconstructions. Distinct from the existing works that rely on a single tri-plane deformation field for dynamic facial modeling, the proposed Tri2-plane leverages the principle of feature pyramids and three top-to-down lateral connections tri-planes for details improvement. It samples and renders facial details at multiple scales, transitioning from the entire face to specific local regions and then to even more refined sub-regions. Moreover, we incorporate a camera-based geometry-aware sliding window method as an augmentation in training, which improves the robustness beyond the canonical space, with a particular improvement in cross-identity generation capabilities. Experimental outcomes indicate that the Tri2-plane not only surpasses existing methodologies but also achieves superior performance across quantitative and qualitative assessments. |
 |
In this paper, we propose an approach to obtain a personalized generative prior with explicit control over a set of attributes. |
 |
In this work, We present the artistic portrait video generation with instructions, a novel task in the field of monocular avatar reconstruction. Based on the requirements, we propose our frameworks, which aims to improve the quality of generated videos and well-worked on different render settings. |

|
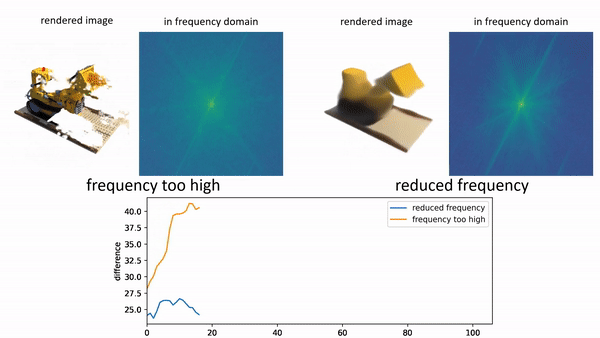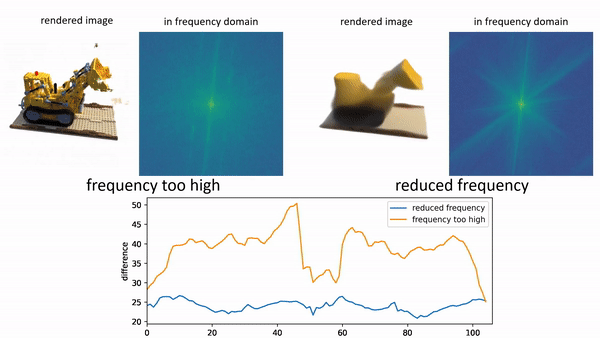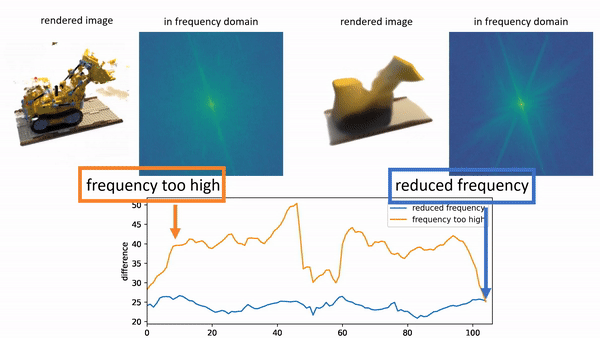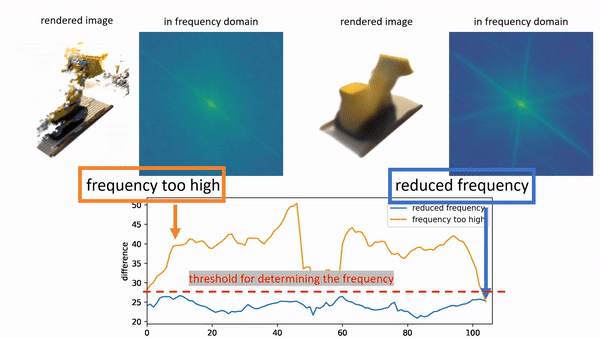
In order to provide 3D shape evaluation that better aligns with human perception, we design an analytic metric named Spectrum AUC Difference (SAUCD) in this work. |
 |
In this paper, we set up an egocentric 3D hand trajectory forecasting task that aims to predict hand trajectories in a 3D space from early observed RGB videos in a first-person view. |
 |
We present a novel type of neural field that uses general radial bases for signal representation. State-of-the-art neural fields typically rely on grid-based representations for storing local neural features and N-dimensional linear kernels for interpolating features at continuous query points. The spatial positions of their neural features are fixed on grid nodes and cannot well adapt to target signals. |
 |
In this work, by leveraging synthetic data, we propose a novel multi-view consistent learning strategy to improve 3D facial landmark detection accuracy on in-the-wild images. The proposed 3D-aware module can be plugged into any learning-based landmark detection algorithm. |
 |
We propose to harness the low-frequency NeRF and leverage it to regularize the high-frequency NeRF so that it will not overfit under the few-shot setting. |

|
We present an efficient framework capable of fast reconstruction, compact modeling, and streamable rendering. |

|
We present a method for performing real-time facial animation of a 3D avatar from binocular video. |

|
3D video avatars allows empowering virtual communications by providing compression, privacy, entertainment and a sense of presence in AR/VR. Best 3D photo-realistic AR/VR avatars driven by video, that can minimize uncanny effects, rely on person-specific models. However, existing person-specific photo-realistic 3D models are not robust to lighting and typically results in missing subtle facial behaviour, and artifacts in the avatar. This is a major drawback for the scalability of these models in communication systems (e.g., Messenger, Skype, FaceTime) and AR/VR. This paper addresses previous limitations by learning a deep learning lighting model, that in combination with a high-quality 3D face tracking algorithm provides a method for subtle and robust facial motion transfer from a regular video to a 3D photo-realistic avatar. Extensive experimental validation and comparisons to other state-of-the-art methods demonstrates the effectiveness of the proposed framework in real-world scenarios with variability in pose, expression and illumination. |
|
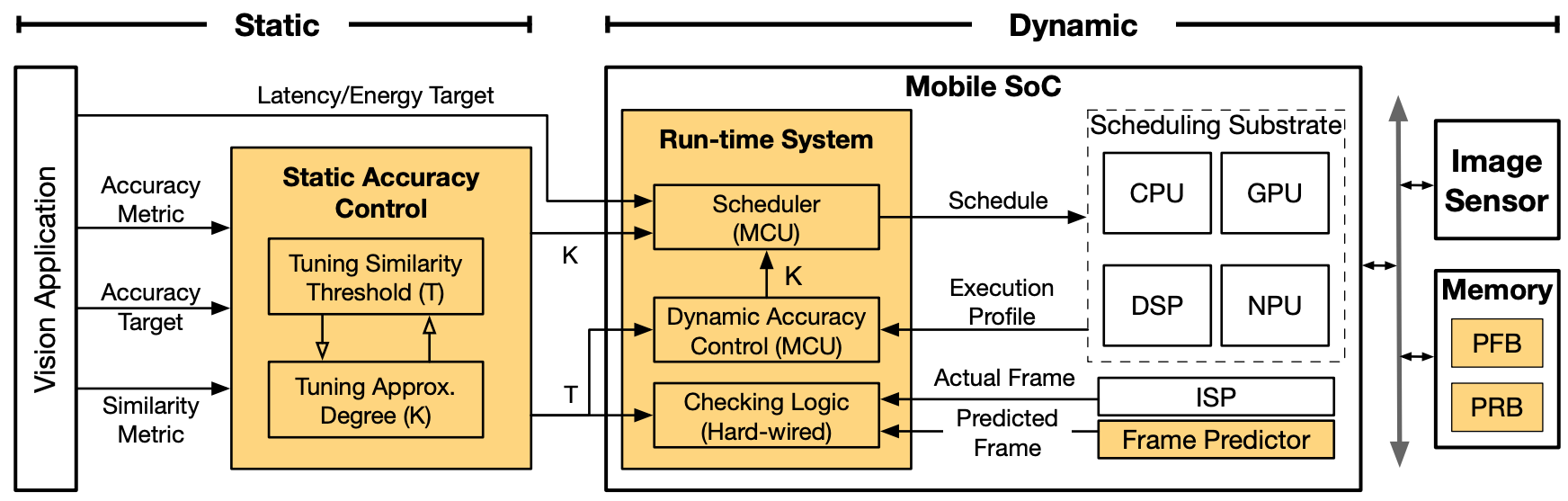
Continuous vision is the cornerstone of a diverse range of intelligent applications found on emerging computing platforms such as autonomous machines and Augmented Reality glasses. A critical issue in today's continuous vision systems is their long end-to-end frame latency, which significantly impacts the system agility and user experience. We find that the long latency is fundamentally caused by the serialized execution model of today's continuous vision pipeline, whose key stages, including sensing, imaging, and vision computations, execute sequentially, leading to long frame latency. |
|
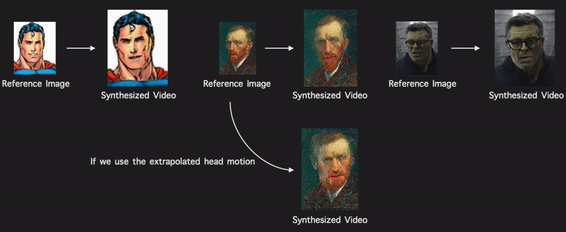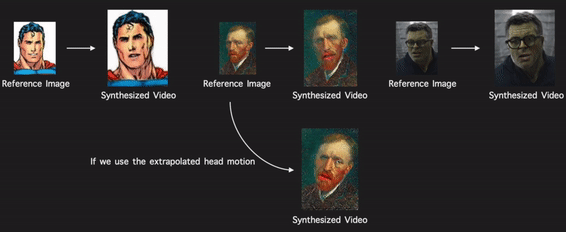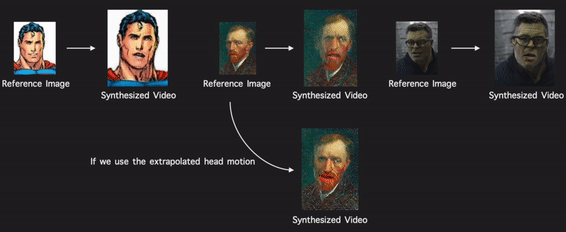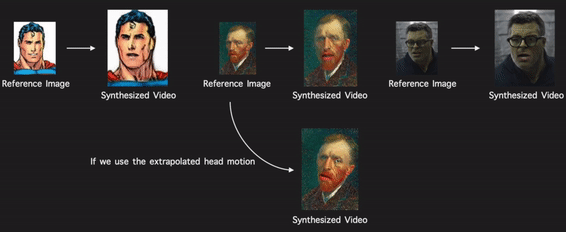
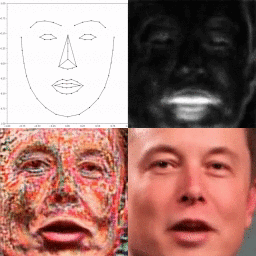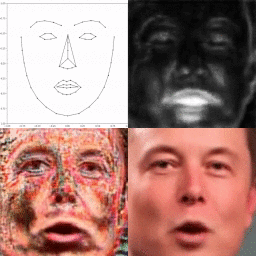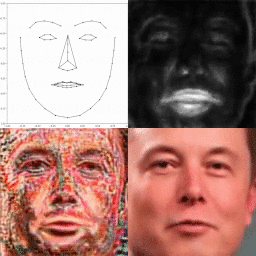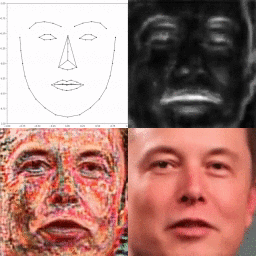
Through modeling the head motion and facial expressions explicitly, manipulating 3D animation carefully, and embedding reference images dynamically, our approach achieves controllable, photo-realistic, and temporally coherent talking-head videos with natural head movements. |

|
We propose to address a challenging example-guided scene image synthesis task. To propagate information between structurally uncorrelated and semantically unaligned scenes, we propose an MSCA module that leverages decoupled cross-attention for adaptive correspondence modeling. With MSCA, we propose a unified model for joint globallocal alignment and image synthesis. We further propose a patch-based self-supervision scheme that enables training. Experiments on the COCO-stuff dataset show significant improvements over the existing methods. Furthermore, our approach provides interpretability and can be extended to other content manipulation tasks. |

|
Pose-guided synthesis aims to generate a new image in an arbitrary target pose while preserving the appearance details from the source image. Existing approaches rely on either hard-coded spatial transformations or 3D body modeling. They often overlook complex non-rigid pose deformation or unmatched occluded regions, thus fail to effectively preserve appearance information. In this paper, we propose an unsupervised pose flow learning scheme that learns to transfer the appearance details from the source image. Based on such learned pose flow, we proposed GarmentNet and SynthesisNet, both of which use multi-scale feature-domain alignment for coarse-to-fine synthesis. Experiments on the DeepFashion, MVC dataset and additional real-world datasets demonstrate that our approach compares favorably with the state-of-the-art methods and generalizes to unseen poses and clothing styles. |

|
In this paper, we propose a pipeline that reconstructs a 3D human shape avatar at a glance. Our approach simultaneously reconstructs the three-dimensional human geometry and whole body texture map with only a single RGB image as input. |

|
We consider a task: given a reference garment image A and another image B with target attribute (collar/sleeve), generate a photo-realistic image which combines the texture from reference A and the new attribute from reference B. |
|
We devise a cascade GAN approach to generate a talking face video, which is robust to different face shapes, view angles, facial characteristics, and noisy audio conditions. Instead of learning a direct mapping from audio to video frames, we propose first to transfer audio to high-level structure, i.e., the facial landmarks, and then to generate video frames conditioned on the landmarks. Compared to a direct audio-to-image approach, our cascade approach avoids fitting spurious correlations between audiovisual signals that are irrelevant to the speech content. We, humans, are sensitive to temporal discontinuities and subtle artifacts in video. To avoid those pixel jittering problems and to enforce the network to focus on audiovisual-correlated regions, we propose a novel dynamically adjustable pixel-wise loss with an attention mechanism. |

|
Given an arbitrary audio speech and one lip image of an arbitrary target identity, generate synthesized lip movements of the target identity saying the speech. To perform well, a model needs to not only consider the retention of target identity, photo-realistic of synthesized images, consistency and smoothness of lip images in a sequence, but more importantly, learn the correlations between audio speech and lip movements. |

|
We have developed algorithms in audio-visual source association that are able to segment corresponding audio-visual data pairs; we have created deep generative neural networks utilizing adversarial training that are able to generate one modality, i.e., audio/visual, from the other modality, i.e., visual/audio. The outputs of cross-modal generation are beneficial to many applications, such as aiding hearing- or visually-impaired and content creation in virtual reality. |

|
In this paper, we introduce a new approach for brain tumor segmentation in MRI scans. DenseNet was initially introduced for the image classification problem. In this work, we explore the potential of densely connected blocks in 3D segmentation tasks. Compared with traditional networks with no skip connections, the improved information flow extracts better features and significantly help the optimization. We take multi-scale receptive fields into account to accurately classify voxels. |

|
Speech perception is a crucial function of the human auditory system, but speech is not only an acoustic signal-visual cues from a talker's face and articulators (lips, teeth, and tongue) carry considerable linguistic information. These cues offer substantial and important improvements to speech comprehension when the acoustic signal suffers degradations like background noise or impaired hearing. However, useful visual cues are not always available, such as when talking on the phone or listening to a podcast. We are developing a system for generating a realistic speaking face from speech audio input. The system uses novel deep neural networks trained on a large audio-visual speech corpus. It is designed to run in real time so that it can be used as an assistive listening device. Previous systems have shown improvements in speech perception only for the most degraded speech. Our design differs notably from earlier ones in that it does not use a language model-instead, it makes a direct transformation from speech audio to face video. This allows the temporal coherence between the acoustic and visual modalities to be preserved, which has been shown to be crucial to cross-modal perceptual binding. |
|
|
|
I am a reviewer of IEEE TIP / IEEE TMM / IEEE Access / Neurocomputing / WACV / CVPR / ICCV / AAAI / ECCV / IEEE-TPAMI / ACM Siggraph, etc. |
|
|
|
This course covers advanced research topics in computer vision with an emphasis on learning structured representations and embeddings. Approaches for learning from unimodal (e.g., images and videos), and multimodal data (e.g., vision and language, vision and audio) will be covered and include topics from structured predications, deep learning and others. The course will be a mix of lecture, student presentation and discussion. Prerequisites: CSC 249/449 or CSC 246/446 or CSC 298/578 (Deep Learning and Graphical Models) or permission of the instructor. This course covers a range of skills and methodologies for the use of spreadsheet-based tools in business modeling and quantitative analysis. We will also develop some introductory techniques for quantitative analysis in R (no prior R programming experience is required). Topics include forecasting using time series regression analysis and ARIMA models; clustering and classification models; linear optimization models and sensitivity analysis; and Monte Carlo simulation. The models and methods covered in CIS 418 can be used across diverse applications in finance, economics, marketing, logistics, and operational management. Companies and organizations in every industry rely heavily on their data, not only for the day-to-day tactical needs of running the business but also to generate information and analysis to support problem solving and decision-making in a wide variety of applications. Database design and management along with systems/techniques for data retrieval, transformation and analysis have the potential to play a key role in business strategy and to create business value and competitive advantage. This course presents the fundamental concepts of database design and use. It provides a study of data models, data description languages, and query facilities including relational algebra and SQL, data normalization, transactions and their properties, physical data organization and indexing, security issues and object databases. It also looks at the new trends in databases, for example, Big Data, MapReduce, and NoSQL. The knowledge of the above topics will be applied in the design and implementation of a database application using a target database management system as part of a semester-long group project. This class offers an introduction to big data concepts, environments, processes, and tools from the perspective of data analysts and data scientists. The course will set the scene for the emergence of big data as an important trend in the business world and explain the technical architectures that make analyzing data at scale possible. The hands-on portion of the class will focus on the major tools of the Hadoop big data ecosystem such as HDFS, Pig, Hive, Sqoop, Hue, Zeppelin, and Spark. In addition, students will gain a broad understanding of the role of MapReduce, Tez, Impala, YARN, and other big data technologies. This course provides some foundations for programming in the R environment. We cover traditional programming concepts such as operators, data structures, control structures, repetition and user-defined functions. In addition, these concepts will be taught in the context of marketing and business analytics problems related to data management and visualization. Other than high-level programming, the students will gain a foundational understanding of how data is can be stored, organized and pulled, in given data analytics context. |
|
|